
Tech Talk: Searching in a large text field with Elasticsearch highlighting and Kibana (Part 2)
In Part 1 of this article series, we presented stored fields and how to modify the default configuration in Elasticsearch. According to our dataset, changing the default configuration didn’t increase the performance. Here, we will discuss the Elasticsearch highlighting feature, its configuration, and the potential performance improvement we can achieve.
It’s often helpful to know which word or token from documents matched our query. In Elasticsearch, the feature of highlighting the token is called, you guessed it, highlighting. This feature can be CPU intensive and time-consuming in particular cases. One of those cases is highlighting from a large text field. We’ll see the different highlighting methods without going deeper into technical details. We’ll then compare the methods’ performance according to our use-cases and dataset.
As a reminder, our dataset is composed of JSON documents containing meta-data like “title” and “author.” An additional field contains the extracted text from the PDF. This field has an average size of 200K characters (200 KB).
Highlighting with Elasticsearch
We need to know if we can optimize the highlighting process in Elasticsearch on our dataset. According to the official documentation, we can parameterize the way we want to highlight our search results. We’ll try to optimize our highlighting performance based on two different parameters:
1. Offset strategy: Postings: it will add an offset location for every term in the inverted index. This way, Elasticsearch will be able to know the location of a specific term without analysis quickly.
Term vector with with_positions_offsets: An additional data structure providing advanced features for scoring results. According to the official documentation, it is supposed to be most efficient for a vast field (> 1 mb). It is also likely to consume much more disk usage.
Note: the default configuration of Elasticsearch is to index documents without calculating any offset.
2. Highlighter: Unified: with BM25 algorithm to score result. This is the default highlighter.
FVH (Fact vector highlighter): with tf–idf algorithm, it requires using a term vector with_positions_offsets.
Plain: It rebuilds a complete tiny in-memory index at query time for every document and field.
By default, Elasticsearch builds neither the postings nor the term vectors. It means the highlighting feature will use the Unified highlighter without offset strategy.
When choosing a particular highlighter, some features won’t be accessible anymore. We recommend you read the official documentation.
Performance measure with Elasticsearch
We have decided to measure the performance of different highlighting configurations. These measures aim to have a ballpark estimation of the best configuration to choose in a proof of concept. These measures could have been biased somehow. Indeed, our test environment is not under production-like steady load but dedicated for its single purpose: ballpark estimation!
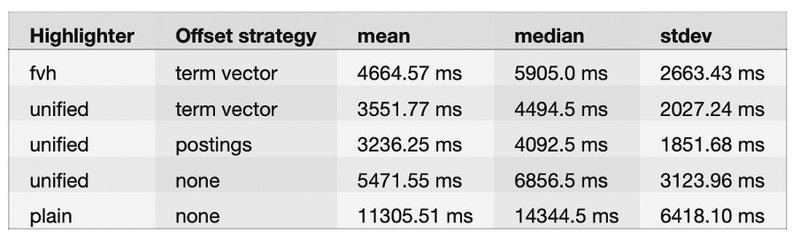
Our test used the “took” result property as a representative amount of milliseconds it took for the query to return. We ran 100 searches requesting a size of 1000 documents on three different indices, each one using a different offset strategy.
Unsurprisingly, the plain highlighter without offset strategy underperforms because of its technical implementation. According to our dataset, the default unified highlighter with postings offset strategy seems to be the most efficient. Moreover, it seems to perform better on our dataset than FVH with the term vector offset strategy. We believe term vector with FVH would fit better with larger text fields as mentioned in the official documentation (> 1 MB)

Term vector obviously consumes the most disk storage because of its additional data structure. We can see that the postings increase disk usage by approximately 20%, which is, in our opinion, still affordable from a business perspective.
If we take the performance and disk usage into account, there is no doubt that postings with a unified highlighter are a good candidate for our implementation.
Search the data with Kibana
When trying to query the data with Kibana, Elasticsearch’s data visualization dashboard software, you’ll see that it is very slow. The issue doesn’t come from Elasticsearch but actually from the Kibana front-end application. Indeed, Kibana will try to load all the large text fields twice into the page.
First, the large text field is part of the source_ field. To speed up Kibana, you have no other choice other than to exclude the large text field from the source. You can do that in the index pattern configuration under the Field filtering_ tab in the newer version of Elasticsearch.
Second, the highlighted part of the query result will contain the complete large text field instead of fragments. A fragment is just a part of the text containing the highlighted value. Let’s take a look at the highlighted part of the generated query when performing a search in the discovery tab:
"highlight": {
"pre_tags": [
"@kibana-highlighted-field@"
],
"post_tags": [
"@/kibana-highlighted-field@"
],
"fields": {
"*": {}
},
"fragment_size": 2147483647
}
What causes the issue is the fragment size which is the maximum value of an integer. Kibana requests the biggest possible highlight fragment resulting in loading the complete large text field. Kibana does so because we believe it is not able for now to show multiple highlighting fragments. There is no other choice to remedy this than to disable the highlighting feature from Kibana's advanced settings.
Conclusion
We have discovered that Kibana does not work with large text fields, especially for the highlighting feature. If we want to link with the previous Part 1 article, it will make sense not to store large text to save disk space by a potential factor of 2. We strongly believe a dedicated front-end application is strongly required to implement highlighting with large text fields for now in our particular use cases.